خبری ترسناک: هوش مصنوعی به سطح انسانی رسید
غزال زیاری: اخیرا سیستم OpenAI o۳ توانست تا در معیار ARC-AGI به امتیاز ۸۵% برسد که به مراتب بالاتر از بهترین امتیاز ثبت شده توسط هوش مصنوعی قبلی یعنی ۵۵ درصد بود و امتیازی هم تراز با میانگین امتیاز انسانی به دست آورد. این سیستم به علاوه در یک آزمون ریاضی خیلی سخت هم نمره خوبی کسب کرد.

ایجاد هوش عمومی مصنوعی (AGI) هدف تعیین شده همه آزمایشگاه های اصلی تحقیقاتی هوش مصنوعی است که در نگاه اول این طور به نظر می رسد که حداقل OpenAI گام بزرگی در جهت محقق کردن این هدف برداشته است.
در این میان که تردیدهای زیادی وجود دارد بسیاری از محققان و توسعه دهندگان هوش مصنوعی حس می کنند که چیزی تغییر کرده و ازنظر خیلی از افراد حالا چشم انداز AGI واقعی تر فوری تر و نزدیک تر از حد انتظار به نظر می رسد؛ اما آیا حق با آن هاست؟
تعمیم و هوش
برای درک اینکه معنی واقعی نتیجه o۳ چیست باید با مفهوم تست ARC-AGI آشنا شوید؛ ازنظر فنی این آزمایش یک سیستم هوش مصنوعی از “کارایی نمونه” در انطباق با چیزی جدید است. (چند نمونه از یک موقعیت جدید که سیستم باید ببیند تا متوجه شود که چگونه کار می کند.)
یک سیستم هوش مصنوعی مثل ChatGPT (GPT-۴) خیلی کارآمد نیست. این سیستم بر روی میلیون ها نمونه از متون انسانی آموزش داده شد و قوانین احتمالی متعددی درباره متحمل ترین ترکیب های کلمات ایجاد کرد. نتیجه در کارهای معمول بسیار خوب بود ولی در کارهای غیرمعمول چندان خوب عمل نمی کرد؛ چراکه داده های کمتر (نمونه های کمتری) در مورد آن وظایف در اختیار داشت.
تا زمانی که سیستم های هوش مصنوعی نتوانند از تعداد مثال های کمی بیاموزند و با نمونه های کاربردی بیشتری سازگار شوند فقط برای کارهای معمول و تکراری و البته مواردی که در آن ها ناکامی و شکست قابل پذیرش باشد مورداستفاده قرار می گیرند. توانایی حل دقیق مسائل ناشناخته قبلی یا مشکلات جدید از نمونه های داده های محدود به عنوان ظرفیت تعمیم شناخته می شود و این به شکل گسترده ای یک عنصر ضروری و اساسی هوش در نظر گرفته می شود.
شبکه ها و الگوها
معیار ARC-AGI برای انطباق کارآمد نمونه با استفاده از مسئله های شبکه ای مربعی کوچک مانند نمونه زیر آزمایش هایی را انجام می دهد و هوش مصنوعی باید الگویی را پیدا کند که شبکه سمت چپ را به شبکه سمت راست تبدیل کند.
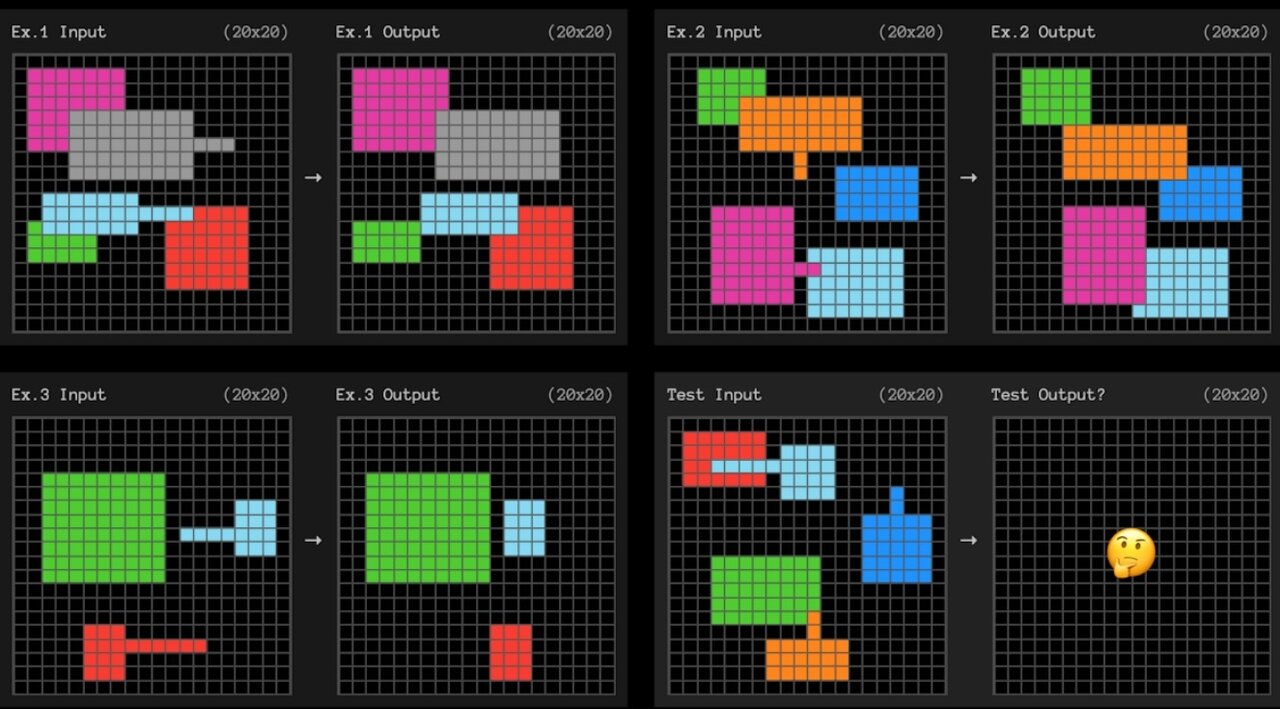
در هر سؤال سه مثال برای یادگیری ارائه می شود. سپس سیستم هوش مصنوعی باید قوانینی که در سه مثال قبلی آموخته را به نمونه چهارم تعمیم دهد. این ها خیلی شبیه به تست های IQ هستند.
قوانین ضعیف و سازگاری
ما دقیقاً نمی دانیم که OpenAI چطور این کار را انجام داده اما نتایج حاکی از آن است که مدل o۳ سازگاری بالایی دارد و از چند مثال محدود می تواند قوانینی را کشف کند که قابل تعمیم دادن باشند.
برای کشف یک الگو نباید فرض های غیرضروری داشته باشیم یا دقیق تر ازآنچه واقعاً هستیم باشیم. در تئوری اگر بتوانید ضعیف ترین قوانینی که کاری که را می خواهید انجام می دهند را شناسایی کنید توانایی خود را برای سازگاری با موقعیت های جدید به حداکثر رسانده اید.
اما منظور از ضعیف ترین قوانین چیست؟ تعریف فنی آن پیچیده است اما معمولاً قوانین ضعیف تر آن هایی هستند که می توان آن ها را با عبارات ساده تری توصیف کرد. مثلاً در مثال بالا یک تعریف ساده از قانون چیزی شبیه به این است: “هر شکلی با یک خط بیرون زده به سمت انتهای آن خط حرکت می کند و هر شکل دیگری را که با آن همپوشانی دارد می پوشاند.”
جستجوی زنجیره های فکری
در شرایطی که هنوز نمی دانیم که OpenAI چگونه به این نتیجه دست یافته بعید است که آن ها عمداً سیستم o۳ را برای یافتن قوانین ضعیف بهینه کرده باشند. بااین حال برای موفقیت در وظایف ARC-AGI باید آن ها را پیدا کرد.
ما می دانیم که OpenAI کار را با یک نسخه همه منظوره از مدل o۳ شروع کرد (که با اکثر مدل های دیگر متفاوت است؛ چراکه می تواند زمان بیشتری را صرف فکر کردن درباره سؤالات دشوار کند) و سپس آن را به طور خاص برای آزمون ARC-AGI آموزش داد.
فرانسوا شوله محقق فرانسوی هوش مصنوعی که این معیار را طراحی کرده براین باور است که o۳ از طریق “زنجیره های فکری” مختلفی که گام هایی برای حل مسئله را توصیف می کنند به جستجو می پردازد و درنهایت بر اساس برخی قاعده های تعریف شده یا هیوریستیک بهترین را انتخاب می کند.
این بی شباهت به نحوه جستجوی سیستم AlphaGo گوگل که ممکن است در توالی های مختلفی از حرکات برای شکست دادن قهرمان جهان Go اقدام می کند نیست.

شما می توانید به این زنجیره های فکری مثل برنامه هایی که با نمونه ها مطابقت دارند نگاه کنید؛ البته اگر مثل هوش مصنوعی Go-playing باشد به یک قانون هیوریستیک یا سست نیاز است تا بتواند تصمیم بگیرد که کدام برنامه بهترین است. ممکن است هزاران برنامه مختلف به ظاهر معتبر تولیدشده باشد. ابتکار ممکن است این باشد که شما “ضعیف ترین” یا “ساده ترین” را انتخاب کنید.
بااین حال اگر مثل AlphaGo باشد به سادگی یک هوش مصنوعی است که یک هیوریستیک ایجاد می کند. این روند برای AlphaGo بود و گوگل مدلی را آموزش داد تا توالی های مختلف حرکت به صورت بهتر یا بدتر از سایرین ارزیابی کند.
چیزی که ما هنوز نمی دانیم
سؤال اینجاست که آیا این واقعاً به AGI نزدیک تر است؟ اگر o۳ این طور کار می کند پس مدل زیربنایی احتمالاً خیلی بهتر از مدل های قبلی نیست. مفاهیمی که مدل را از زبان می آموزد ممکن است برای تعمیم مناسب تر از قبل نباشد و در عوض ممکن است شاهد یک “زنجیره فکری” تعمیم پذیرتر باشیم که از طریق مراحل اضافی آموزش هیوریستیک مخصوص برای این تست پیدا می شود.
تقریباً همه چیز در مورد o۳ ناشناخته است. OpenAI افشای اطلاعات را به چند ارائه رسانه ای و آزمایش اولیه برای تعداد محدودی از محققان آزمایشگاه ها و مؤسسات ایمنی هوش مصنوعی محدود کرده و درنتیجه درک واقعی پتانسیل o۳ مستلزم تلاش های گسترده ای از ارزیابی و درک توزیع ظرفیت های آن گرفته تا تعداد دفعات شکست و تعداد دفعات موفقیت آن خواهد بود.
زمانی که درنهایت o۳ منتشر شود تصور بهتری خواهیم داشت که آیا تقریباً به اندازه یک انسان معمولی سازگار است یا خیر. اگر این چنین باشد این امر تأثیری بزرگ انقلابی و اقتصادی خواهد داشت و عصر جدیدی از هوش سرعت یافته که قابلیت خودکاری برای بهبود دارد را آغاز خواهد کرد. ما به معیارهای جدیدی برای خود AGI و بررسی ای جدی در مورد نحوه اداره آن نیاز خواهیم داشت.
در غیر این صورت بازهم این یک نتیجه چشمگیر خواهد بود. هرچند که زندگی روزمره ما تقریباً مانند قبل خواهد ماند.
منبع: theconversation
۲۲۷۲۲۷